
Hudi,正式的全称是Hadoop Upsert Delete and Incremental,从源代码里可以看到这个项目最初的名字是hoodie,和现在的名字发音相同。但这个名字还是透露了一些信息的,那就是Hudi项目最初的设计目标:在hadoop上实现update和delete操作。Hudi经常被拿来跟Delta,Iceberg一起,并称为“数据湖三剑客”。
众所众知的是,无论是HDFS还是云平台的对象存储(例如aws的s3,阿里云的oss等),都不支持update而只能overwrite,因此要实现update和delete功能,就必须在底层存储之上做文章。Hudi于是应运而生。
Hudi最初的设计目标就是在hadoop上实现数据的update,于是这里的核心问题就是
如何在一个只能overwrite的文件系统上实现update操作?
Hudi解决了这个问题,使用了一种很简单的思想,那就是
把一个完整的文件拆分为多个“小文件”,当需要更新其中某条记录时,只要把包含这条记录的“小文件”给重写一遍即可。
Hudi的标志性功能——Upsert
Hudi最初的版本只支持COW表,Copy on Write(简称COW)或Merge on Read(简称MOR)
接下来我会用一个例子直观地展示下COW表的upsert是如何实现的。
首先,假设我们向一张Hudi表中预先写入了5行数据,如下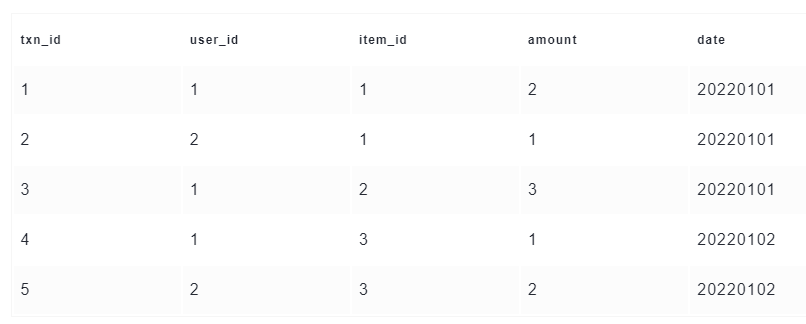
这时在我们的hdfs里面,会有下面2个目录,以及1个隐藏的.hoodie目录。文件名分为两部分,fileId是Hudi中的一个概念,后面会做解释,001则是commitId
如图:
可以看到,属于20220101分区的3条数据保存在一个parquet文件:fileId1_001.parquet,属于20220102分区的2条数据则保存在另一个parquet文件:fileId2_001.parquet。
然后我们再写入3条新的数据。其中有2条数据是新增,1条数据是更新。写入的数据如下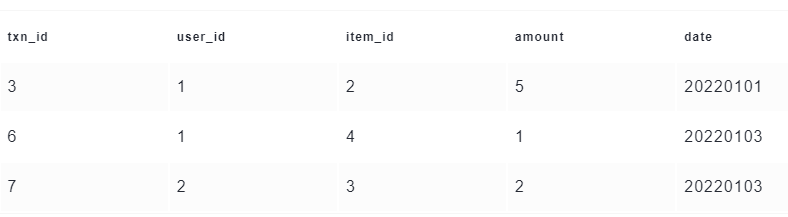
写入完成后,hdfs里面的文件结构会变成这样,注意.hoodie这个目录,里面保存了hudi的元数据
如图:
可以看到,更新的那一条记录,实际被写入到了同一个分区下的新文件:fileId1_002.parquet。这个新文件的fileId和上一个相同,只不过commitId变成了002。同时还有一个新文件:fileId3_001.parquet。
update到这里就算完成了,那么使用这张表的用户又是如何读到更新以后的数据呢?Hudi客户端在读取这张表时,会根据.hoodie目录下保存的元数据信息,获知需要读取的文件是:fileId1_002.parquet,fileId2_001.parquet,fileId3_001.parquet。这些文件里保存的正是最新的数据。
读取的最新文件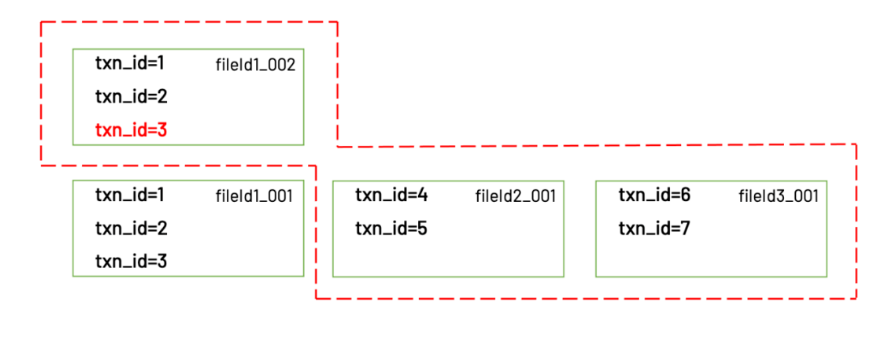
以上就是Hudi实现update的原理
发表评论
取消回复