
本文介绍了 hudi的COW表和MOR表
Hudi表分为Copy on Write和Merge on Read两种类型,Copy on Write(简称COW)或Merge on Read(简称MOR),Merge on Read是对Copy on Write的优化,主要是写入性能优化。
对于COW表,每次更新都会生成一个新的文件,里面包括了更新的数据以及属于同一个文件但没有被更新的老数据。所以这个文件比较大,写入也会比较慢。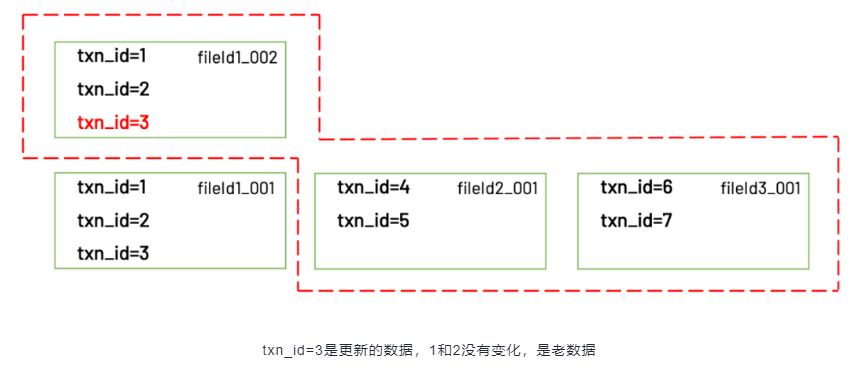
为了加快写入(主要是update)的速度,Hudi引入了MOR表。和COW表最大的不同就是,MOR表在更新时只会把更新的那部分数据写入一个.log文件,因为.log文件不包含老数据,也不涉及tagging,又是顺序写入的,所以写入会非常快。而当客户端要读取数据时,会有两种选择:
-
读取时动态地把.log文件和原始数据文件(称为base文件)进行merge
-
异步地把.log文件和base文件merge,如果merge还没完成,只能读到上个版本的数据
无论是哪一种办法,都有利有弊。
第一种办法的优点是数据保证最新,缺点是读取的性能较差。
第二种办法的优点是读取的性能和COW表相同,缺点是异步merge(称为compaction)有一定的延迟。这也就是Hudi官网上展示的snapshot query和read optimised query的差异来源

发表评论
取消回复