SQL 统计行数 count()函数,count(*)与count(1)区别
count()函数返回查询的总行数。
COUNT(column_name) 函数返回指定列的值的数目(NULL 不计入):
SELECT COUNT(column_name) FROM table_name;
COUNT(*) 函数返回表中的记录数:
SELECT COUNT(*) FROM table_name;
COUNT(DISTINCT column_name) 语法
COUNT(DISTINCT column_name) 函数返回指定列的非重复值的数目:
SELECT COUNT(DISTINCT column_name) FROM table_name;
count(*) 与 count(1)区别
1、执行效果上:
count(1),其实就是计算一共有多少符合条件的行。1并不是表示第一个字段,而是表示一个固定值。
其实就可以想成表中有这么一个字段,这个字段就是固定值1,count(1),就是计算一共有多少个1。count(*),执行时会把星号翻译成字段的具体名字,效果也是一样的,不过多了一个翻译的动作,比固定值的方式效率稍微低一些。
2、执行效率上:
他们之间根据不同情况会有些许区别,MySQL 会对count()做优化。(1)如果表中只有一列,则count( )效率最优。(2)如果表有多列,且存在主键,count (主键列名)效率最优,其次是:count (1) >count( *)。(3)如果表有多列,且不存在主键,则count(1 )效率优于count( *)
3、从执行结果来说:
1、count(1)和count ()之间没有区别,因为count () count (1)都不会去过滤
2、(排除)空值,但count (列名)就有区别了,因为count (列名)会过滤空值。
count()函数查询实例
实例数据 表access_log
+-----+---------+-------+------------+
| aid | site_id | count | date |
+-----+---------+-------+------------+
| 1 | 1 | 45 | 2016-05-10 |
| 2 | 3 | 100 | 2016-05-13 |
| 3 | 1 | 230 | 2016-05-14 |
| 4 | 2 | 10 | 2016-05-14 |
| 5 | 5 | 205 | 2016-05-14 |
| 6 | 4 | 13 | 2016-05-15 |
| 7 | 3 | 220 | 2016-05-15 |
| 8 | 5 | 545 | 2016-05-16 |
| 9 | 3 | 201 | 2016-05-17 |
+-----+---------+-------+------------+
计算 "access_log" 表中 "site_id"=3 的总访问量:
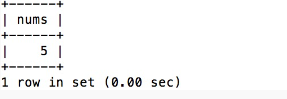
SELECT COUNT(count) AS nums FROM access_log WHERE site_id=3;
计算 "access_log" 表中总记录数:
SELECT COUNT(*) AS nums FROM access_log;
计算 "access_log" 表中不同 site_id 的记录数:
SELECT COUNT(DISTINCT site_id) AS nums FROM access_log;