
按照数据的分类,搜索也分为两种:
-
对结构化数据的搜索:如对数据库的搜索,用SQL语句。再如对元数据的搜索,如利用windows搜索对文件名,类型,修改时间进行搜索等。
-
对非结构化数据的搜索:如利用windows的搜索也可以搜索文件内容,Linux下的grep命令,再如用Google和百度可以搜索大量内容数据。
对非结构化数据也即对全文数据的搜索主要有两种方法:
-
顺序扫描法(Serial Scanning):所谓顺序扫描,比如要找内容包含某一个字符串的文件,就是一个文档一个文档的看,对于每一个文档,从头看到尾,如果此文档包含此字符串,则此文档为我们要找的文件,接着看下一个文件,直到扫描完所有的文件。
-
全文检索(Full-text Search):将非结构化数据中的一部分信息提取出来,重新组织,使其变得有一定结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对较快的目的,这部分从非结构化数据中提取出的然后重新组织的信息,我们称之索引。
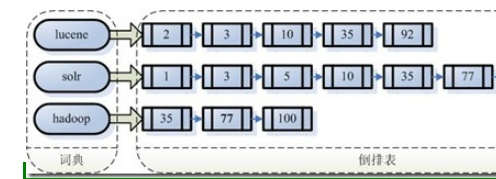
左边保存的是一系列字符串,称为词典。
每个字符串都指向包含此字符串的文档(Document)链表,此文档链表称为倒排表(Posting List)。
Lucene的文件扩展名
索引文件说明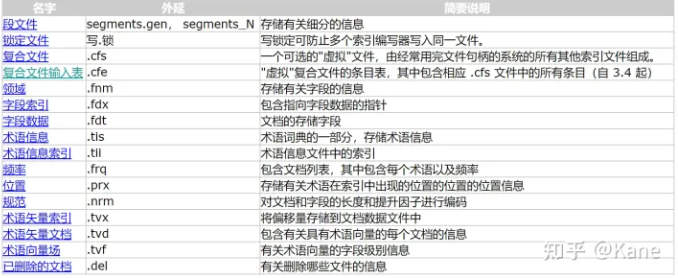
Lucene的索引结构中,即保存了正向信息,也保存了反向信息。
所谓正向信息:
按层次保存了从索引,一直到词的包含关系:索引(Index) –> 段(segment) –> 文档(Document) –> 域(Field) –> 词(Term)(这些概念稍后会介绍)
也即此索引包含了哪些段,每个段包含了那些文档,每个文档包含了那些域,每个域包含了那些词。
既然是层次结构,则每个层次都保存了本层次的信息以及下一层次的元信息,也即属性信息。
如上图,包含正向信息的文件有:
segments_N保存了此索引包含多少个段,每个段包含多少篇文档。
- .fnm保存了此段包含了多少个域,每个域的名称及索引方式。
- .fdx,.fdt保存了此段包含的所有文档,每篇文档包含了多少域,每个域保存了那些信息。
- .tvx,.tvd,.tvf保存了此段包含多少文档,每篇文档包含了多少域,每个域包含了多少词,每个词的字符串,位置等信息。
所谓反向信息:
保存了词典到倒排表的映射:词(Term) –> 文档(Document)
如上图,包含反向信息的文件有:
- .tis,.tii保存了词典(Term Dictionary),也即此段包含的所有的词按字典顺序的排序。
- .frq保存了倒排表,也即包含每个词的文档ID列表。
- .prx保存了倒排表中每个词在包含此词的文档中的位置。
索引文件结构
索引(index)
Lucene的索引由许多个文件组成,这些文件放在同一个目录下
段(segment)
一个Lucene的索引由多个段组成,段与段之间是独立的。添加新的文档时可以生成新的段,达到阈值(段的个数,段中包含的文件数等)时,不同的段可以合并。
在文件夹下,具有相同前缀的文件属于同一个段
segments.gen 和 segments_N(N表示一个具体数字,eg:segments_5)是段的元数据文件,他们保存了段的属性信息。
文档(document)
文档时建索引的基本单位,一个段中可以包含多篇文档
新添加的文档时单独保存在一个新生成的段中,随着段的合并,不同的文档会合并到至相同的段中。
域(Field)
一个文档有可由多个域(Field)组成,比如一篇新闻,有 标题,作者,正文等多个属性,这些属性可以看作是文档的域。
不同的域可以指定不同的索引方式,比如指定不同的分词方式,是否构建索引,是否存储等
词(Term)
词 是索引的最小单位,是经过词法分词和语言处理后的字符串
发表评论
取消回复